Sutra sits between your product decisions and your AI coding agents. Build implementation-complete specs — with acceptance criteria, edge cases, API contracts, and dependencies — then export them in formats agents can act on immediately.
"A computer can never be held accountable, therefore a computer must never make a management decision."
— IBM, 1979
Your name is on the spec. The agent's name is on the code. That's the right order.
Why Sutra
AI agents build exactly what you tell them. The gap between what you meant and what you wrote is where bugs, rework, and hallucinated features come from.
Sutra closes that gap — a spec authoring canvas that gives your agents testable acceptance criteria, edge cases, API contracts, and dependency maps before a single line of code is written.
Creating a Map
✏️ From Scratch
Enter project name and Jira key. Blank canvas — add epics, flows, and stories manually. All fields are available from the start.
⬇ From Jira
Enter project key, fetch epics, select which to import. Stories land with Jira keys pre-linked.
📄 From JSON
Import a previously exported Sutra JSON. Full fidelity — all flows, NFRs, API contracts, and spec fields preserved.
Canvas Controls
Element
Interaction
Epic header
Double-click to rename inline · ✎ Edit Epic to open modal — title is editable at the top of the modal · Drag ⠿ to reorder · Right-click for context menu
Flow header
Click ✎ to edit name, description, API contracts · Drag ⠿ to reorder · Right-click for context menu
Story card
Click to select for push · ✎ to edit · ⧉ to duplicate · Right-click for context menu
Jira pill
Click MBA-12 pill on any story to open that ticket in Jira
Progress bar
Spec completeness per flow and map-wide. Hover topbar bar to see gaps.
Zoom
−%+ controls in toolbar, or Ctrl+scroll on canvas
Quick-jump strip
Sticky bar at canvas bottom — click any epic pill to scroll it into view
Story Edit Dialog
📋 Step 1 — Story
Title — "As a [role] I can [action]"
Release — Assign to a milestone
Description / AC — Format as AC: ... per line. Supports markdown.
⚡ Step 2 — Spec
Edge Cases — Boundary conditions, error states
Open Questions — Unresolved decisions for the agent to flag
Test Type — Unit / Integration / E2E
🔗 Step 3 — Dependencies
Internal — Own APIs the agent calls autonomously
External — Third-party or human-gated. Agent pauses and waits.
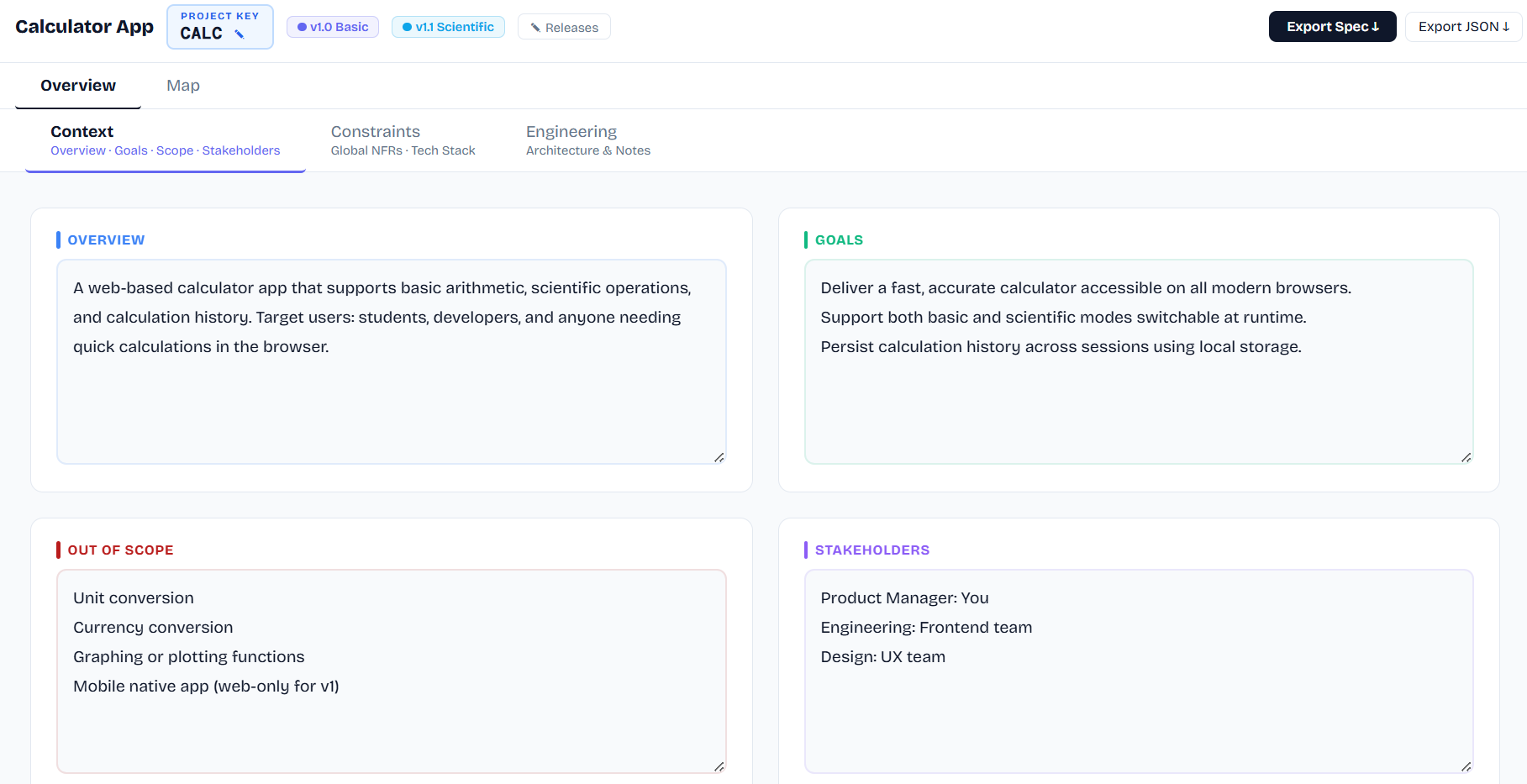
Overview Tab Fields
Field
What it does
Description
One-paragraph overview of the system and who it serves
Goals
Measurable business outcomes — the agent understands success criteria
Out of Scope
Explicitly excluded features — prevents the agent building things you don't want
Tech Stack
Drives test framework resolution — integration tests on frontend-only get Jest + MSW, not Supertest
Global NFRs
Cross-cutting constraints applied to every epic and story in the spec
Engineering Notes
Architecture decisions, coding conventions. Agent reads this before touching any file.
Releases
Milestones or phases. The exported Build Instructions targets the first release.
💡
Existing codebase? Click + Insert Template in Engineering Notes to add a structured block telling the agent what's already built and where — preventing rewrites of working code.
What is Sutra
Sutra is a story mapping tool built for teams using AI coding agents. Traditional tickets are written for humans — thin, ambiguous, and leaving implementation decisions to the developer. AI agents need more: testable acceptance criteria, edge cases, API contracts, test type declarations, and dependency maps that tell the agent what it can call autonomously vs what needs a human in the loop.
Sutra gives you a structured canvas to build that context, sync it with Jira, and export it in agent-ready formats.
ℹ️
The mental model: Sutra is your spec authoring environment. Jira is your delivery tracking system. Sutra doesn't replace Jira — it completes it. Jira is the source of truth for status, sprint, and assignee. Sutra is the source of truth for specification.
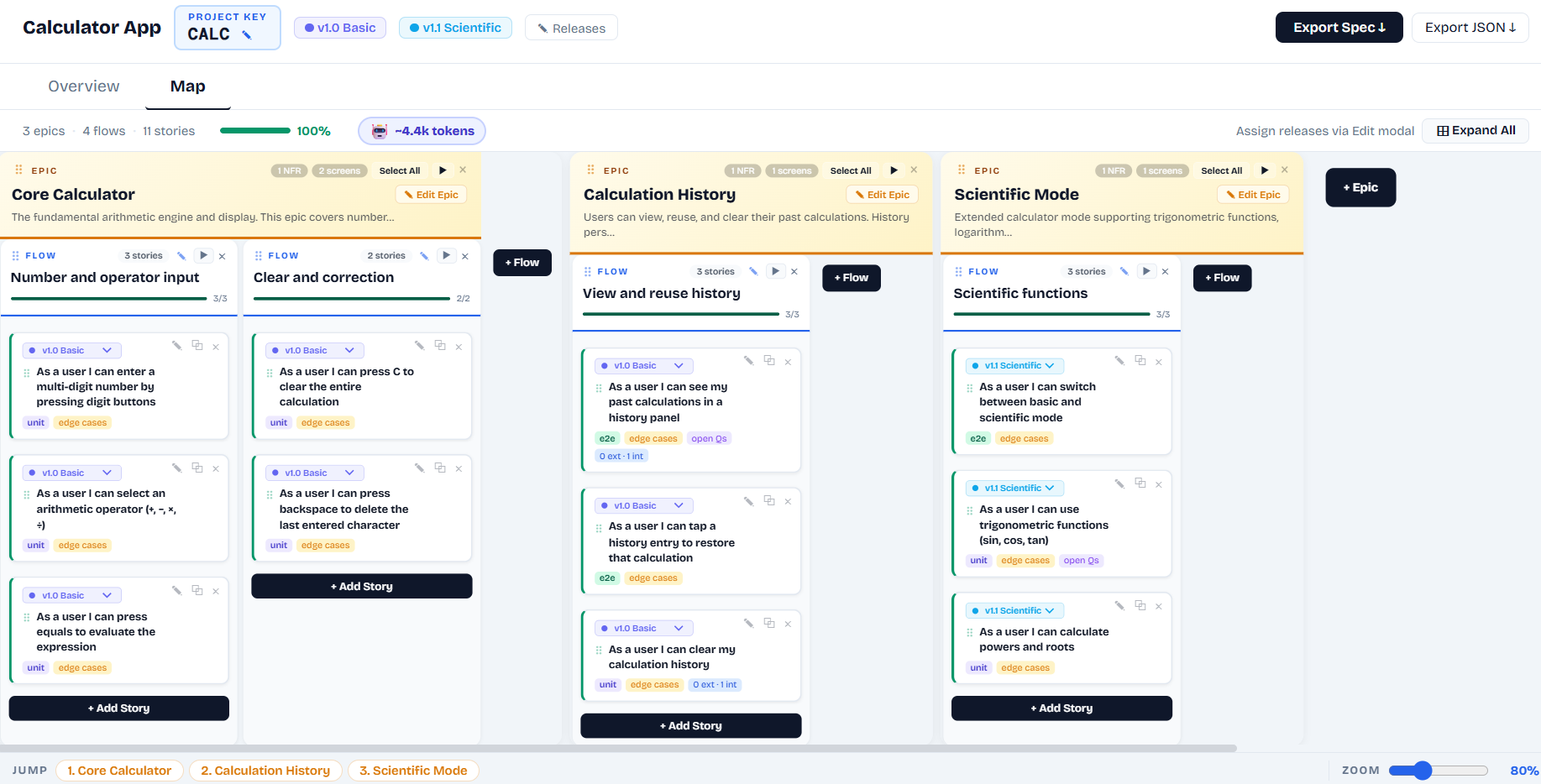
🟡
Epic
A major functional area or user journey. Contains flows. Maps to a Jira Epic. Has description, NFRs, and optional screen map.
🔵
Flow
A user journey step within an epic. Contains stories. Has description and structured API contracts. A Sutra concept — not a Jira issue type.
🟢
Story
An atomic requirement. Maps to a Jira issue. Has AC, edge cases, test type, and dependencies. The unit the agent implements.
1
Create or import a map
Start from scratch, import from Jira, or generate from a document using the AI template. Your map is the spec authoring surface.
2
Enrich stories to spec-ready quality
Add acceptance criteria, edge cases, test types, dependencies. Add API contracts to flows. Set NFRs at epic or global level.
3
Sync back to Jira optional
If you're using Jira, push enriched stories to create new tickets or update existing ones. Push epics with full flow and API contract context. For Jira flows see sutrasdd.app/#jira.
4
Export to your agent
Export as single markdown spec or Claude Code project structure. Drop into your repo and run your agent.
What Sutra Does vs What Jira Does
Sutra's strengths
Structured AC per story
Edge cases and open questions
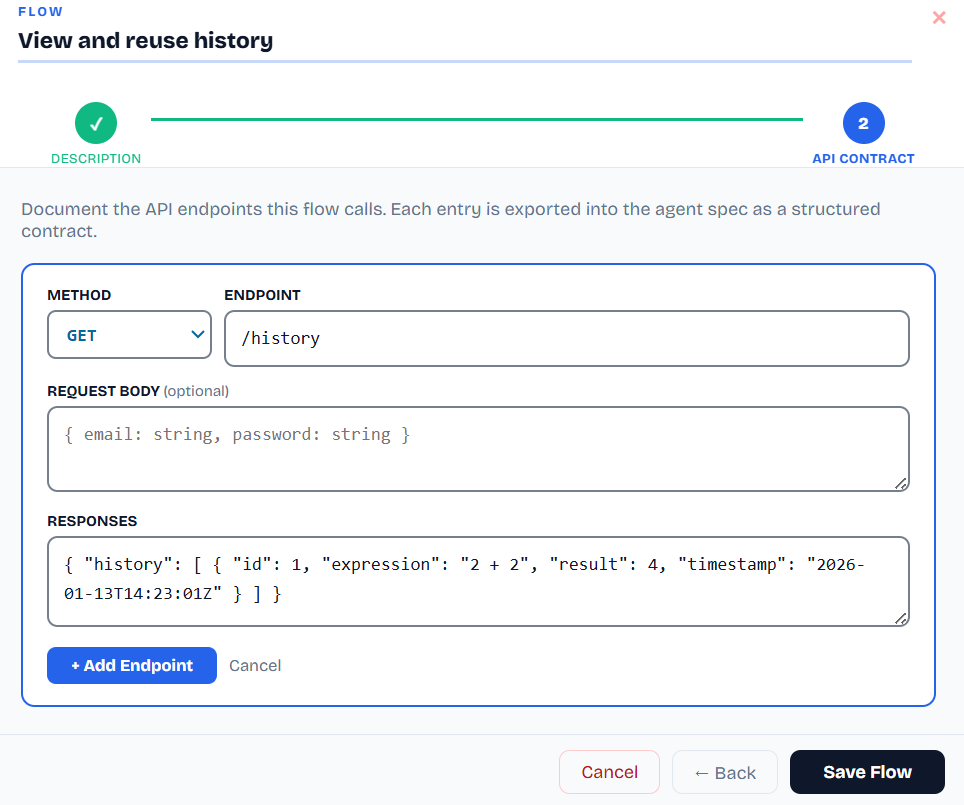
API contract authoring at flow level
Test type → framework resolution
Internal vs external dependency mapping
Global and epic-level NFRs
Screen maps for UI projects
Agent-ready spec export
Visual story map with zoom
Jira's strengths
Sprint planning and velocity
Story status (To Do / In Progress / Done)
Assignee, reporter, watchers
Comments and activity log
Workflow automations
Reporting and burndown charts
Time tracking and estimation
CI/CD pipeline integration
ℹ️
Jira is the source of truth for delivery. Sutra is the source of truth for specification. Use both — they serve different purposes.
Setup
1
Log into Jira in this browser
Sutra uses your existing browser session — no API key required. Open your Jira instance and log in before using Jira features.
2
Open Settings
Click ⚙ Settings in the sidebar. A blue dot appears on first install to signal unvisited settings. The Jira tab opens by default and shows a contextual tip explaining the setup.
3
Enter your Jira base URL
Paste https://company.atlassian.net (no trailing slash). Works for Jira Cloud and self-hosted.
4
Set project key per map
Click the project key pill in the topbar. Required before any push.
Scenario
What happens
Story with no Jira key
Creates a new issue. Stamps the key on the story card.
Story with Jira key
Updates the existing issue — title and description/AC only. Never touches status, assignee, or sprint.
Bulk push
Select stories by clicking cards (or Select All on epic header) → Push Stories in topbar.
Single story push
Right-click any story card → Push to Jira / Update in Jira.
Epic state
Button shown
What happens
Not linked to Jira
⬆ Push to Jira
Creates a Jira Epic. Stamps key. Description populated with NFRs, screens, numbered flows, and API contracts.
Linked, has content in Sutra
⬆ Update [key]
Overwrites the Jira epic description with current Sutra content.
Linked, empty in Sutra
⬇ Sync from Jira
Pulls title and description from Jira into Sutra.
⚠️
Issue type validation: Sutra validates the issue type before linking. Entering a Story or Task key instead of an Epic shows an error and refuses to link.
Jira Caveats
⚠ Sync pulls text only — not structured data
Syncing an epic pulls title and description as plain text. Flows, NFRs, and API contracts do not reconstruct as structured Sutra fields. Workaround: use Export JSON as your source of truth for round-trips.
⚠ Jira-native stories lack structured fields
Stories created directly in Jira don't have test type, edge cases, or dependency maps. After importing, add these fields manually in the Spec and Dependencies tabs before exporting to an agent.
⚠ Epic description is overwritten on Update
Clicking ⬆ Update [key] overwrites the entire Jira epic description. Manual edits made directly in Jira will be lost. Always edit epic context in Sutra, not in Jira.
⚠ Sutra never touches Jira metadata
Status, assignee, sprint, priority, labels — Sutra never reads or writes these. Fully managed in Jira. Sutra only pushes title and description/AC.
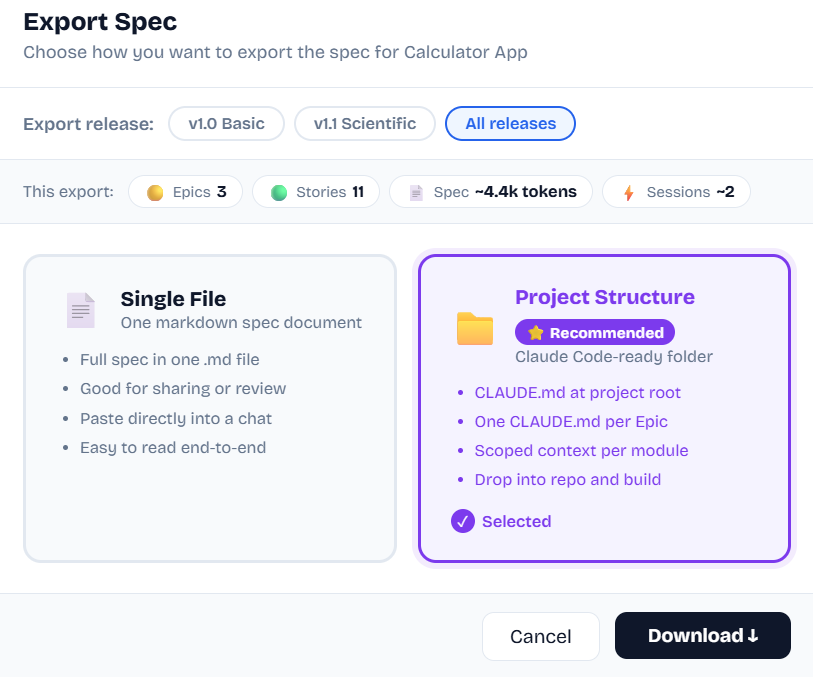
Export Formats
📄
Single Spec File
One markdown file — overview, tech stack, NFRs, every epic and story with full ACs, edge cases, API contracts. Paste into any AI assistant or share for review.
📁
Claude Code Structure
A zip ready to drop into your repo. Root CLAUDE.md, one folder per epic, full spec.md. Includes auto-generated Build Instructions. Run Claude Code immediately.
🗂
JSON Export
Full lossless map data. Share between machines, feed to AI, or back up. Import back via New Map → Import → From File.
Claude Code Project Structure
project-name/
├── CLAUDE.md ← Start here — overview, tech stack, global constraints, build instructions
├── spec.md ← Full story detail — AC, edge cases, deps, open questions
├── docs/
│ ├── architecture.md ← Engineering notes (if set)
│ └── release-plan.md ← Release overview with story counts
└── epics/
├── 01-sign-up/
│ └── CLAUDE.md ← Epic context — screens, NFRs, API contracts, DoD checklist
└── 02-payments/
└── CLAUDE.md
💡
The root CLAUDE.md includes a Build Instructions section auto-populated from your release plan, epic order, test framework mapping, and global NFRs. The agent reads this before writing a single line of code.
Org Guardrails
Set organisation-wide non-negotiable constraints once in ⛨ Org Guardrails in the sidebar. They're injected at the top of every spec export across all maps — every agent session starts with them, regardless of project.
What to put here
Coding standards that apply everywhere
Security non-negotiables (e.g. "never use eval()")
Data handling rules (e.g. "all PII encrypted at rest")
API conventions (e.g. "all responses within 200ms at p95")
What belongs in Engineering Notes instead
Project-specific architecture decisions
Codebase conventions for this map only
Existing code patterns to follow
Stack-specific implementation notes
ℹ️
First time you click ⛨ Org Guardrails, a brief explainer appears. The amber dot on the button disappears after your first visit.
Workflow A — PRD / ICD to Story Map
You have a requirements document and want a fully populated Sutra map without manual entry.
1
Download AI Map Template
Settings → Utilities → Download AI Map Template. Contains master prompt and full schema.
2
Upload to Claude
Open claude.ai. Upload the template JSON and your PRD or ICD as attachments in the same message.
3
Prompt Claude
"Follow the instructions in the _sutra block to generate a Sutra story map from the attached document. Return only valid JSON with no markdown fences."
4
Import the JSON
Save Claude's output as a .json file. In Sutra: + New Map → Import → From File.
5
Review and enrich
Claude does a good first pass but won't get everything right. Review each story — fill in edge cases, add API contracts to flows, verify test types.
Workflow B — Plan with Claude Before Building
You want to catch spec gaps and get an implementation plan before handing the spec to an agent. A human-in-the-loop review pass before the build starts.
1
Export your map as JSON
Export JSON from the topbar. Full structured spec — every field, every story.
2
Give it to Claude with a planning prompt
Upload to claude.ai. Prompt: "Read this Sutra story map. Identify spec gaps, ambiguous AC, and missing edge cases. Produce an implementation plan — story sequencing, dependencies, open questions. Do not generate code. Return the updated JSON with planning notes in the relevant openQuestions fields."
3
Review Claude's plan
Claude returns a plan and updated JSON. Resolve conflicts, answer open questions, adjust story scope.
4
Import the updated JSON
+ New Map → Import → From File. Planning notes appear as open questions on stories. Resolve them, then export the final spec for building.
⚠️
Importing Claude's JSON creates a new map — it does not overwrite your existing one. Review both before deciding which to keep.
Workflow C — Existing Codebase
Adding features to an existing product. You don't want the agent to rewrite working code.
1
Open Overview → Engineering tab
Click + Insert Template in the green Existing Codebase card. A structured block is appended to your engineering notes.
2
Fill in the template
Set the codebase root path. List what's already built per epic. Add key files the agent should read first.
3
Export as Claude Code structure
Engineering notes land verbatim in root CLAUDE.md. The agent reads this before touching any file — extends existing code instead of rewriting it.
Workflow D — Jira Round-Trip
You built a map in Sutra and want to share it with a teammate or use it on another device.
✅ Recommended: JSON export
Export as JSON from the topbar. Lossless — all epics, flows, stories, NFRs, API contracts preserved. Share the file or import on another device.
🔄 Via Jira sync (limited)
Create empty map → import epics from Jira → sync each epic. Stories import with Jira keys. Flows, NFRs, and API contracts won't reconstruct as structured fields — they'll be in the description as text.
Use for Jira-native epics only. For Sutra-originated content, always use JSON.
Tips
💡 Spec completeness bar
The progress bar in the topbar scores how spec-complete your map is. Description + test type + edge cases per story each contribute. Hover to see exactly what's missing. Green = agent-ready.
💡 Right-click for everything
Right-click any epic header, flow header, or story card for a context menu with Edit, Duplicate (stories only), Push to Jira, and Delete. Faster than hunting for the ✎ button.
💡 Quick-jump strip
On maps with multiple epics, a sticky strip appears at the bottom of the canvas with numbered epic pills. Click any pill to scroll that epic into view — essential on large maps.
💡 Dependencies drive agent behaviour
Internal means the agent can call that service autonomously. External means the agent must stop and wait for a human. The most important field for agentic workflows — fill it in for every story that has a dependency.
💡 Open questions as agent signals
Open Questions appear in the spec with a ⚠ marker. The agent is explicitly instructed to flag these and not guess. Use them to surface decisions that haven't been made yet.
💡 Global NFRs are powerful
A global NFR like "All API endpoints must require JWT" applies to every story in the entire spec. Set it once in Overview → NFRs. Injected above every epic in the export — the agent never misses it.
💡 JSON is your backup
Export JSON regularly — it's your lossless backup. Preserves everything: flows, NFRs, API contracts, edge cases, open questions, dependency maps, release assignments, and Jira keys. Store it in your repo.
💡 Always declare tech stack
The tech stack drives test framework resolution in the exported spec. Without it, integration tests get a generic fallback message. Fill in Overview → Tech Stack before exporting.
Keyboard Shortcuts
Shortcut
Action
Ctrl + Scroll on canvas
Zoom canvas in / out (pinch gesture on trackpad also works)
Pinch gesture anywhere
Zooms canvas only — browser zoom is blocked app-wide
Ctrl + =
Zoom in
Ctrl + −
Zoom out
Ctrl + 0
Reset zoom to 100%
Escape
Close any open modal (disabled during the scripted guided tour)
Double-click epic label
Rename epic inline
Right-click any card
Context menu — Edit / Duplicate / Push / Delete
Common Questions
What's the difference between a Flow and a Story?
A Flow is a user journey within an epic — "Registration", "Make Payment". It's a container that holds stories and provides API contract context. A Story is an atomic requirement within that flow. One flow typically has 2–6 stories. The agent implements story by story but reads the flow's API contracts for context.
Can I use Sutra without Jira?
Completely. Jira integration is optional. Create maps from scratch, export specs, hand to agents — no Jira connection needed.
My stories came from Jira — how do I make them agent-ready?
Imported Jira stories have title and description but no edge cases, test type, or dependencies. Open each story's ✎ edit dialog and fill in the Spec tab and Dependencies tab. The progress bar shows what's missing.
I synced an epic from Jira but flows aren't showing as flow cards
Expected. Sync pulls title and description as plain text — it doesn't reconstruct flows as structured Sutra data. The content is in the description field and will appear in your spec export. For full round-trips, use Export JSON and Import JSON.
How do I share a map with a teammate?
Export as JSON from the topbar. Send the file. Teammate opens Sutra → + New Map → Import → From File. Full map appears — all epics, flows, stories, spec fields, and Jira keys intact.
What's in your exported spec
A Sutra spec is a structured markdown document your agent can act on immediately — no interpretation required. Every export includes:
📋
Acceptance Criteria
Testable conditions that define "done" per story.
⚡
Edge Cases
Boundary conditions and failure modes the agent must handle.
🔌
API Contracts
Structured endpoint definitions scoped to each flow.
🔒
NFRs
Non-functional rules injected into every story automatically.
🔗
Dependencies
What the agent resolves autonomously vs what needs a human.
🧪
Test Type
Unit, integration, or E2E declared per story.
🏗️
Engineering Notes
Your stack, conventions, and what's already built — prepended to every export.
Using the spec with Claude Code
Claude Code reads your project, understands context, and implements stories one by one.
1
Open Claude Code in your project
Run claude in your terminal from the project root. Claude Code reads your existing codebase before doing anything.
2
Share the spec
Paste the markdown contents directly, or reference the exported file path.
3
Use this prompt
💡
Template: "Read this spec carefully. Implement the stories in order, starting with [Epic Name]. For each story: implement the feature, write the test indicated by the test type, and confirm AC is met before moving on. Ask me if anything is ambiguous."
4
Review each story
Claude Code implements story by story. Review each before approving.
Tips for better results
💡
Single file vs project structure: Use "Single file" for smaller features. Use "Project structure" for Claude Code — one file per epic keeps context focused per session.
💡
Engineering notes matter: Prepended to every export. Tell the agent about your stack, shared patterns, what's already built, and conventions it must follow.
💡
Export after each release: Sutra stamps the engineering notes with what was built. Future exports tell the agent "these stories are done — don't rewrite them."
⚠️
Don't skip edge cases: The most common agent failure mode is missing edge cases. "AC: user can divide" gets you happy path only. "AC: division by zero returns Error" changes the output entirely.
Community
Coming Soon. :)
Privacy Policy
Last updated: March 2026
Sutra is a Chrome extension. This policy explains what data Sutra collects, how it is used, and how it is stored.
Data We Collect
We collect nothing. Sutra does not collect, transmit, or store any personal data on external servers. There are no analytics, no tracking pixels, no third-party data sharing, and no accounts.
All data you create in Sutra — maps, stories, epics, flows, settings — is stored exclusively in your browser's local storage (chrome.storage.local) on your own device. It never leaves your machine unless you explicitly export it.
Jira Integration
When you use Sutra's Jira integration, Sutra communicates directly from your browser to your Atlassian instance using your existing browser session cookies. Sutra does not store, proxy, or log your Jira credentials or API tokens. No Jira data passes through any external servers — the connection is entirely between your browser and your Atlassian instance.
Permissions
Sutra requests the following Chrome permissions:
💾
storage
To save your maps and settings locally in your browser using chrome.storage.local.
🔗
activeTab
To communicate with your Jira instance when you trigger a push or sync from the extension.
No other permissions are requested. Sutra does not access your browsing history, other tabs, or any data outside of the extension itself.
Your Data
Because all data is stored locally, you have full control:
Delete any map at any time from within the extension.
Export your maps as JSON at any time for backup or portability.
Uninstalling Sutra removes all locally stored data.
Changes to This Policy
If this policy changes materially, it will be updated here and noted in the extension release notes. We will never introduce data collection without clearly disclosing it.
Contact
Questions? Reach out via the Chrome Web Store listing or the Sutra website at sutrasdd.app.